Predicting human similarity judgments with distributional models: The value of word associations
Abstract
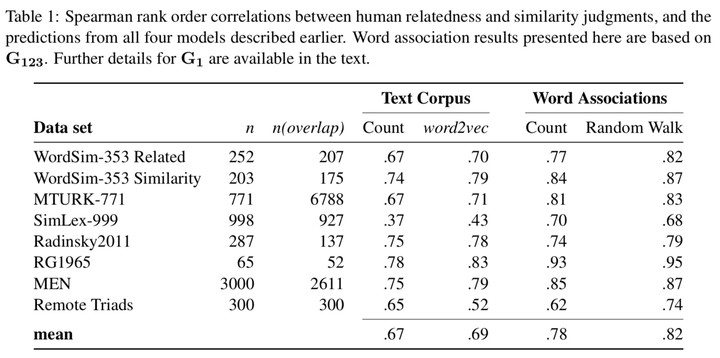
Most distributional lexico-semantic models derive their representations based on external language resources such as text corpora. In this study, we propose that internal language models, that are more closely aligned to the mental representations of words could provide important in- sights into cognitive science, including linguistics. Doing so allows us to reflect upon theoretical questions regarding the structure of the mental lexicon, and also puts into perspective a number of assumptions underlying recently proposed distributional text-based models. In particular, we focus on word-embedding models which have been proposed to learn aspects of word meaning in a manner similar to humans. These are contrasted with internal language models derived from a new extensive data set of word associations. Using relatedness and similarity judgments we evaluate these models and find that the word-association-based internal language models consistently outperform current state-of-the art text-based external language models, often with a large margin. These results are not just a performance improvement; they also have implications for our understanding of how distributional knowledge is used by people.